Webarchive Recovery is a tool that allows you to download an entire site from Webarchive (web.archive.org) for any date in HTML format. All images, styles, and scripts will also be saved (except those downloaded from other resources). It is possible to select dates for each specific page with a preview.
Create task
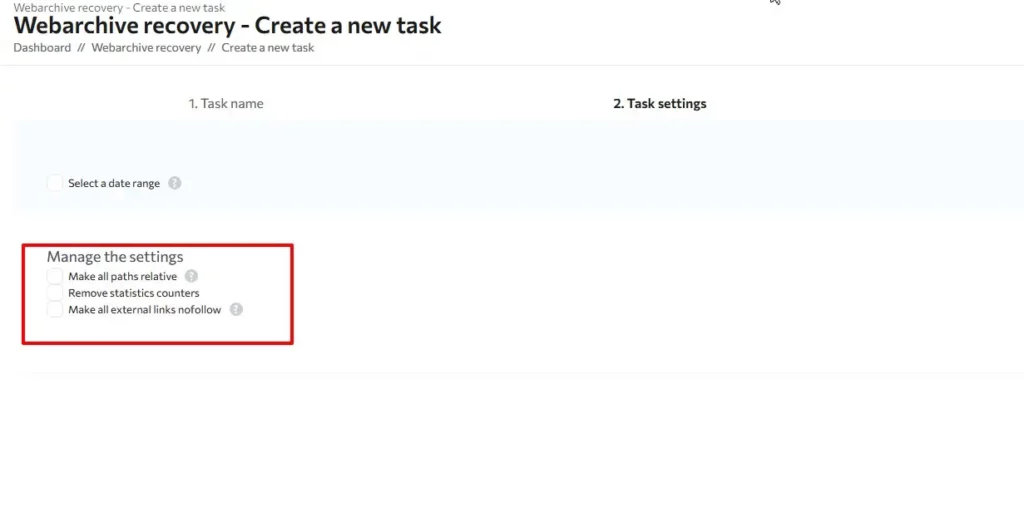
Enter the name of the task and go to the next step to the task settings. There is a “Select period” checkbox here to download documents by a set date. If this box is not activated, the system will download the document on the last available date.
We recommend that you do not activate this checkbox unless you know exactly what date you need the copy from. If the domain is old, for example, and you know exactly what date you want the copy from, then simply select it in the calendar:
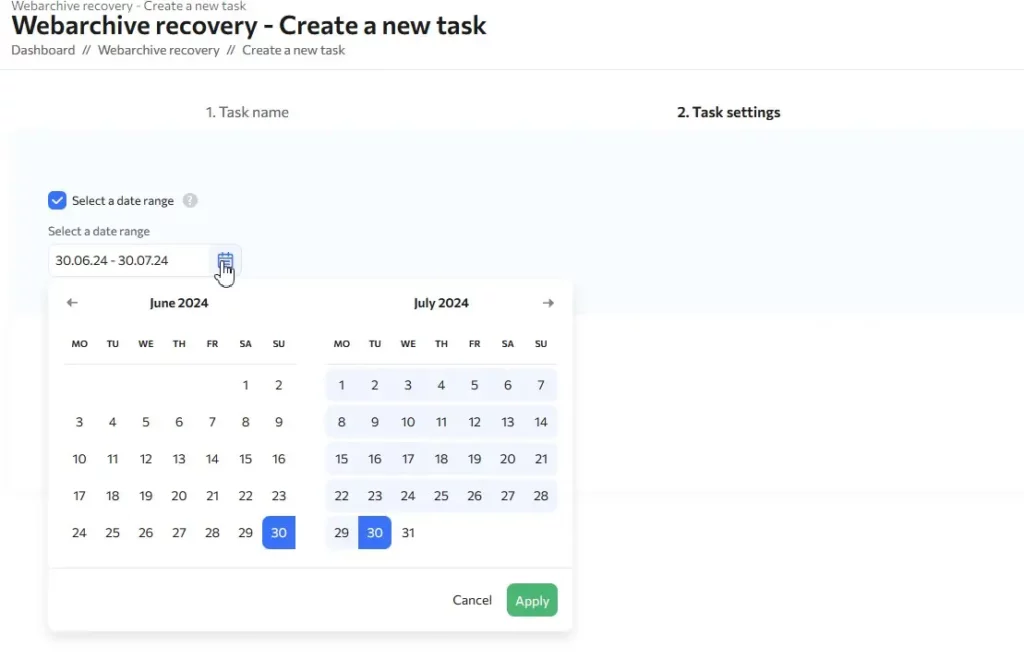
The “Make all paths relative” and “Remove statistics counters” checkboxes are recommended to always be left on: they will help you avoid various problems when transferring a copy of the site to your server.
Next, go to step three and enter the domain address (without http:// and www) to be restored and then click “Add domain”:
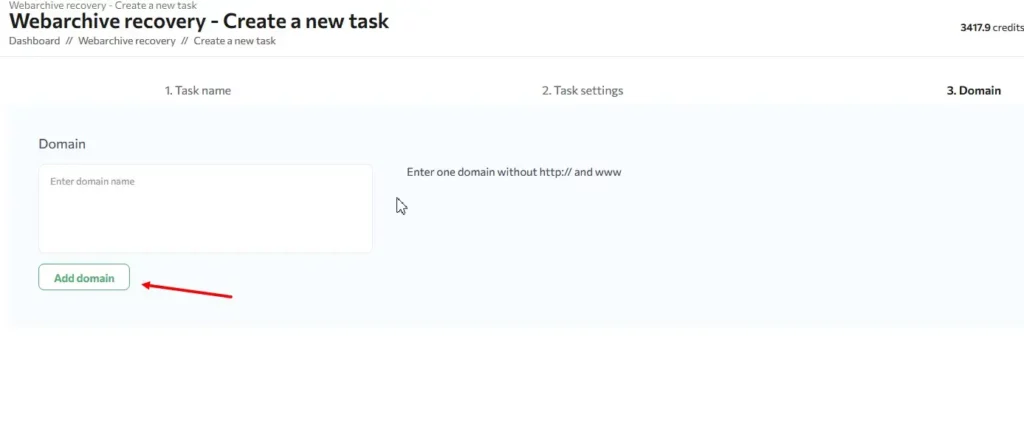
Important: Only 1 domain per task is supported at the moment, so if you need to restore multiple sites, you will need to create multiple tasks.
Next, click “Start task” and confirm the launch.
Results
After launching, the task will appear on the listing under “Webarchive recovery”. You can monitor the status of its execution. When the task is ready, a “Download” button will appear, which will allow you to download a ZIP archive with a copy of the site to your computer and then upload it to the hosting.
To go to the task and view the results, simply click on the task name. You will see a list of downloaded files with columns:
- File name
- File type
- Save date
- Actions
You can sort the list by any column. There is also a form for searching by file name. You can use pagination or specify how many results you want to see on a page.
You can also click on URLs of uploaded files: they are available for viewing and open in a new tab (opens a copy already saved on our server).
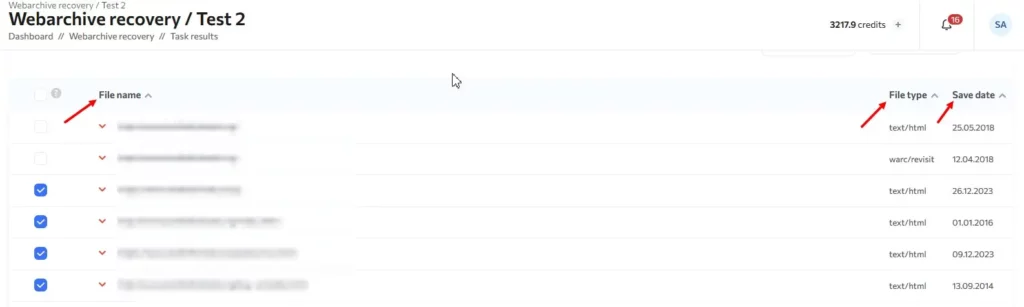
If some pages are downloaded incorrectly, you can select a different copy date for each of them by clicking on the icon next to the URL and selecting the snapshot for the desired date.
If there are no other dates, Webarchive does not contain additional copies of the page you have selected.
If there is a URL you don’t need, simply disable the checkbox next to it, so it won’t appear in the archive upon download.
Next, to restore the site on your server, download the ZIP archive from the task, browse it, and unpack via FTP to the root directory of your hosting domain:
After launching the site, carefully review how it works, go through all the pages, and check that all links, buttons, styles, and images work, because sometimes Webarchive does not contain all the pages of the site and needs to be adjusted.
Is this article helpful?
 162
162
 0
0