


If your website or app returns the wrong HTTP status code, it can confuse users, block search engines, and break API integrations. Two of the most common mistakes involve the 401 Unauthorized and 403 Forbidden responses.
Both codes signal access problems, but for different reasons. A 401 means the user hasn’t authenticated correctly — they need to log in or provide a valid token. A 403 means the user is identified, but not allowed to proceed — access is denied by policy.
Understanding when to use 401 vs 403 helps prevent user frustration, keeps bots from being blocked, and ensures accurate server responses. In this guide, you’ll learn how these codes work, where to use them, how they affect SEO, and how to monitor and fix them.
- What is a 401 Unauthorized Status Code?
- What is a 403 Forbidden Status Code?
- 401 vs 403: Comparative Analysis
- RFC References and Their Importance
- User vs. Service Access Control
- Common Misconceptions
- Real-world Examples
- How 401 and 403 Status Codes Impact SEO
- How to Monitor 401 and 403 HTTP Errors on Your Website
- How to Fix 401 Errors
- How to Fix 403 Errors
What is a 401 Unauthorized Status Code?
The 401 Unauthorized status code means that the website or server needs to know who you are before giving access — but it either didn’t get that information or couldn’t verify it. In other words, the system is asking you to log in or prove your identity.
This often happens when:
- You visit a page that requires login, but you haven’t logged in yet;
- Your session has expired and you need to sign in again;
- The login details or access token you sent are wrong or outdated.
Websites, APIs, and online tools use this code to protect private areas like personal dashboards, admin panels, or data that only certain users should see.
A 401 response also tells the browser or app how to try again, usually through a login prompt or message. Once the user logs in with correct details, the error goes away.
When to Use 401 Unauthorized
This error code is used when a user hasn’t logged in or the system doesn’t recognize the login attempt. Here are common cases:
- No login information was sent;
- The login details (like password or token) are incorrect or expired;
- A session has timed out after inactivity;
- A secure page was opened in a new tab without logging in again.
Examples:
- A user tries to access their account page after closing the browser;
- An app makes a request without including the login token;
- A visitor tries to open a protected area but hasn’t logged in yet.
The 401 error is authentication-specific, telling the system: “We don’t know who this is — ask them to log in”. If the identity is not known or the credentials fail validation, the server must return this status.
What is a 403 Forbidden Status Code?
A 403 Forbidden status code indicates that the server understands the client’s request and recognizes the user, but access to the requested resource is denied. Unlike a 401 error, this code is not about missing or invalid authentication credentials — it’s about permission.
In other words, the user has already provided valid authentication credentials, or the server otherwise knows who they are, but they lack the required privileges to access the specific resource. This often happens in systems with access control where certain users are allowed to view or modify content, and others are not.
The 403 response reflects an intentional access denial based on server-side rules. It may be triggered by role restrictions, blocked IP addresses, file system permissions, or security policies that apply even to authenticated users.
Examples include:
- A logged-in user trying to access an admin-only dashboard;
- A valid API client with insufficient permissions for a restricted endpoint;
- Googlebot encountering a firewall rule that blocks certain user agents.
When to Use 403 Forbidden
You should return a 403 error when a user is logged in (or their identity is known), but they don’t have permission to see or use something. Here are typical situations:
- A user is logged in but tries to access an admin dashboard without admin rights;
- An API key is valid but doesn’t include permission to perform certain actions;
- Access is blocked based on country, IP address, or security rules;
- A firewall or server setting is actively preventing the request;
- A file or folder on the server is restricted and not meant to be public.
Examples:
- A customer logs into your service but tries to open a settings page for managers only;
- A bot or scraper tries to access content that’s restricted by your firewall;
- A logged-in user with a free account tries to access premium features.
403 means the client is recognized, but not authorized: “We know who you are, but you can’t go here”.
401 vs 403: Comparative Analysis
The main difference between the 401 Unauthorized and 403 Forbidden status codes lies in how the server handles authentication and access. A 401 response tells the client to provide valid authentication credentials, while a 403 response means the user is recognized but lacks the necessary permissions to access the requested resource.
Here’s a detailed comparison:
| Feature | 401 Unauthorized | 403 Forbidden |
| Meaning | Missing or invalid authentication credentials | Access denied despite valid authentication |
| User status | Unauthenticated users | Authenticated users with insufficient permissions |
| Can it be resolved by login? | Yes — if the user provides valid credentials | No — even with valid authentication, access is denied |
| Authorization header | Server includes WWW-Authenticate header field | Usually not included |
| Access control behavior | Server challenges for authentication | Server enforces access denial for specific resource |
| Common cause | Invalid credentials or authentication fails | Lack of required privileges or access restriction |
| SEO risk | Bots may not index due to missing credentials | Bots may be blocked if access denial is misconfigured |
| Typical use case | Login prompts, API requiring token | Role-based restrictions, IP blocks, firewall rules |
| Server returns | Prompts for authentication | Denies access without further challenge |
Using the correct error code matters. If you return 403 instead of 401, users won’t know they need to log in. If you return 401 instead of 403, they might be prompted to re-authenticate even though they simply don’t have access.
Properly distinguishing between these two ensures that access control works as intended, both for real users and for services like Googlebot that need to crawl specific content.
RFC References and Their Importance
To understand how 401 and 403 status codes should behave, we turn to the official technical documents called RFCs (Request for Comments). These are guidelines published by the Internet Engineering Task Force (IETF) that define how web technologies work.
Two key RFCs explain these status codes:
- RFC 7235 — This document describes the 401 Unauthorized status. It defines how servers should request authentication using the WWW-Authenticate header and how clients should respond. It’s the foundation for how login prompts and token-based authentication are handled.
- RFC 7231 — This one defines the 403 Forbidden status. It explains that access is denied even when authentication has succeeded, and clarifies that further attempts to authenticate will not change the outcome.
Why does this matter?
Using these RFCs as a reference ensures that your website or API behaves in a way that’s predictable and compatible with browsers, search engines, and other tools. For example:
- Without following RFC 7235, your login system might fail to trigger a browser login prompt.
- Ignoring RFC 7231 might lead to users being wrongly prompted to re-authenticate when access is simply restricted.
Developers often refer to these documents when building authentication systems, configuring APIs, or debugging access errors. Following them helps avoid unexpected problems and improves security, consistency, and reliability across the web.
User vs. Service Access Control
Modern platforms serve both human users and machine clients (like microservices). The 401 vs. 403 logic often differs:
| Audience | Error Trigger | Code | Fix |
| User | Not logged in | 401 | Redirect to login page |
| User | No access rights | 403 | Show “Access Denied” message |
| API Service | Expired access token | 401 | Refresh token |
| API Service | Insufficient permissions | 403 | Adjust token scopes or roles |
By separating these flows, you improve UX and reduce false errors.
Common Misconceptions
Many developers, marketers, and even SEO specialists confuse how and when to use 401 and 403 status codes. This leads to broken access logic, bad user experience, and indexing problems. Here are the most frequent mistakes — and why they matter:
❌ Myth: 401 means access is denied
✅ Reality: 401 doesn’t mean “access denied” — it means “please authenticate.” It should only be used when the client hasn’t logged in or has sent invalid credentials. If a user is logged in but blocked due to permissions, that’s a 403.
❌ Myth: 403 is always related to login
✅ Reality: 403 doesn’t require login at all. Some firewalls or server configurations block entire IP ranges, methods (like POST), or countries — and return 403. It’s not always tied to user roles or sessions.
❌ Myth: Both codes can be used interchangeably
✅ Reality: These codes serve different purposes. Using them incorrectly leads to misleading responses. For example, returning a 403 when a user isn’t logged in hides the fact that authentication is needed.
❌ Myth: Fixing 403 just means re-authenticating
✅ Reality: Unlike 401, re-authentication won’t fix a 403. You need to change roles, permissions, or server access rules.
❌ Myth: Bots and search engines understand the difference automatically
✅ Reality: Search engines treat 401 and 403 very differently. If a public page returns 401, it may never get crawled. If it returns 403 without reason, the page may be dropped from the index entirely.
To avoid these problems, always test your status codes on real users, bots, and API clients. And when in doubt — check the RFC definitions.
Real-world Examples
Seeing how major platforms implement 401 and 403 status codes can help clarify when each one should be used. These real-world examples show how error codes relate to valid authentication credentials, access control, and specific resource permissions.
Google Drive
If you’re not logged in and try to open a private document, the server returns a 401 Unauthorized — you must provide valid credentials to continue. If you are logged in but not granted access, a 403 Forbidden is returned, indicating access denial to a specific resource.
GitHub API
Requests made without an API token return a 401 Unauthorized. If the token is valid but lacks the required privileges to perform an action (like deleting a repository), the server returns a 403 Forbidden due to insufficient permissions.
Amazon Web Services (AWS)
When using expired or invalid authentication credentials, AWS returns a 401. If your credentials are valid but your user role doesn’t allow access to the particular endpoint (e.g., a restricted S3 bucket), AWS responds with 403.
WordPress Admin Panel
Accessing /wp-admin/ without logging in prompts a 401 or login redirect. Logging in with an account that lacks admin rights results in a 403, because the authenticated user lacks necessary permissions.
Firewall-based blocking (e.g., Cloudflare)
Even fully authenticated users may receive a 403 response if access control settings deny access based on IP address or location. These are examples where valid authentication isn’t enough to grant access.
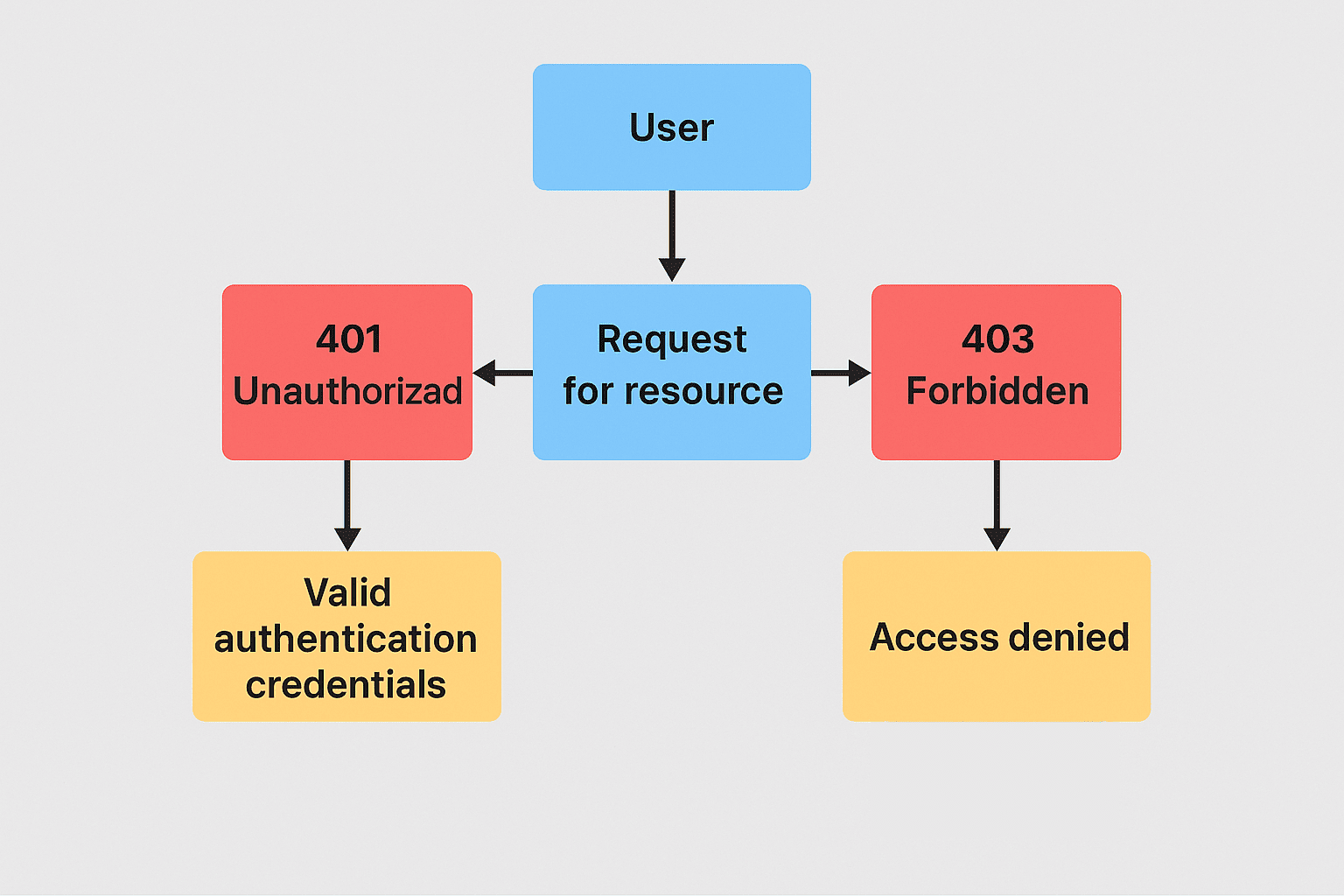
In each case, the server returns the correct status code based on whether the issue is with authentication (401) or with authorization (403). This precise handling ensures users — and bots — receive the correct response for their situation.
How 401 and 403 Status Codes Impact SEO
Status codes directly affect search engine behavior. If search bots encounter a 401 or 403, they may:
- Be blocked from crawling pages;
- Waste crawl budget on inaccessible content;
- Abandon indexing prematurely.
Misconfigurations (e.g. 403 on sitemap.xml) cause critical crawl failures. Proper status codes help Googlebot and others decide whether to retry, skip, or mark the content inaccessible.
Search Engines Can’t Index Pages
Search engines must be able to freely access a page in order to evaluate and include it in their index. If a page returns a 401 Unauthorized status, bots cannot authenticate and will abandon the request. Similarly, a 403 Forbidden response results in a full block — even when the bot is known.
If these status codes are applied to publicly available resources, like landing pages, blog articles, or product listings, they create barriers for indexing. Without valid authentication credentials, crawlers have no way to access the content. As a result, your pages disappear from search results, and your traffic drops.
Crawl Budget is Wasted on Restricted Pages
Google allocates a limited number of crawl requests to each site — this is your crawl budget. When crawlers repeatedly hit 401 and 403 errors on URLs included in your sitemap or internal links, that budget is wasted.
Instead of crawling new or updated content, bots spend time requesting pages they can’t access. This not only delays indexing for legitimate pages but also signals poor technical setup. By denying access to the wrong sections, you reduce crawl efficiency across your entire domain.
To fix this, avoid linking to pages that return restricted status codes unless they’re meant to be private. Remove them from your sitemap or grant access where appropriate.
Users Get Frustrated and Leave Your Pages Quickly
Status codes don’t just affect bots — they shape user experience too. If real users are met with unexpected 401 or 403 errors, they’re likely to bounce immediately. This leads to a poor engagement signal and potential ranking decline.
Imagine a user clicks on a search result, expecting to read a guide — but is hit with a 403 Forbidden. Without a clear explanation or a way to proceed, they leave. If this happens often, Google may see the page as low quality or inaccessible.
Make sure error messages are clear, custom-branded, and informative. When access denial is necessary, provide users with alternative options or links back to accessible content.
Rankings May Drop Over Time
Google’s algorithms track how often content is available and accessible. Pages that consistently return 401 or 403 errors may be flagged as unreliable or irrelevant. Over time, this can result in demotion or complete removal from the index.
Access denial should be used carefully. Always ensure that any restricted resource isn’t part of your core SEO strategy. If a ranking URL becomes blocked due to server changes or permission issues, rankings may begin to decline within days.
How to Monitor 401 and 403 HTTP Errors on Your Website
To prevent SEO and UX issues, monitor 401 and 403 errors using tools like Google Search Console, log analysis, and technical SEO platforms.
Identifying 401 and 403 Error Codes with Google Search Console
In GSC, go to “Pages” → “Why pages aren’t indexed”. Look for:
- Blocked due to unauthorized request (401)
- Blocked due to access forbidden (403)
Review affected URLs. GSC may also show these errors in the coverage or crawl stats section.
You can export affected URLs and cross-check them against your intended access policies. Are they admin pages? Then OK. Are they blog posts or product pages? Then it’s a misconfiguration.
Fix by adjusting firewall rules, login gates, or meta tags.
Identifying 401 and 403 Error Codes with Website Audit Tools
Tools like Rush Analytics, Screaming Frog, and Ahrefs crawl your site and log status codes. Filter reports to show 401 and 403 errors.
Rush Analytics’ Site Audit shows which pages block bots and when they were last crawled. Use this data to:
- Spot firewall rules misapplied to public URLs
- Fix authentication prompts on indexable content
- Improve your sitemap structure
The audit tool also shows trends over time, so you can spot if something broke during deployment.
Identifying 401 and 403 Error Codes with Log File Analysis
Web server logs contain every request and response. Analyzing logs helps:
- Understand when bots/users hit 401/403
- See which IPs are being blocked
- Detect patterns (e.g., frequent bot blocks)
Use tools like GoAccess, Loggly, or ELK stack to analyze logs.
Pro tip: Focus on status codes + user agent = find out what’s blocking Googlebot.
Combine with crawl stats to validate whether these blocks are hurting your visibility.
Free 7 days access to all tools. No credit card required!
Попробовать бесплатно
How to Fix 401 Errors — “Blocked due to unauthorized request (401)” in GSC
When Google Search Console (GSC) reports a 401 error, it means Googlebot tried to access a page but couldn’t authenticate. This usually happens if the page requires login, session tokens, or API keys — and Googlebot doesn’t have them.
To fix it:
- Remove authentication for public content: If the page should be visible to everyone (e.g., blog posts, product pages), make sure it doesn’t require login or session cookies.
- Allow anonymous access: Configure your server or CMS so Googlebot can view the page without identifying itself.
- Check robots.txt: Make sure the page isn’t accidentally disallowed, forcing Googlebot to retry unauthorized paths.
- Whitelist Googlebot IPs: If a firewall is blocking unauthenticated bots, explicitly allow known Googlebot IPs.
- Disable auth prompts for Googlebot: Use user-agent detection or header-based rules to skip login challenges when the visitor is a crawler.
After making changes, return to GSC and click “Validate fix”. Google will re-crawl the URL and remove the error if authentication is no longer required.
Remember: never require login for indexable pages. Googlebot doesn’t log in.
How to Fix 403 Errors — “Blocked due to access forbidden (403)” in GSC
A 403 error in GSC means Googlebot accessed the page but was explicitly denied. The bot was recognized — but blocked due to server rules, firewall settings, or permission restrictions.

To fix it:
- Check access permissions: Make sure the page isn’t limited to certain user roles or IP addresses.
- Allow known bots: Update firewalls (e.g., Cloudflare, AWS WAF) or server configs (nginx, Apache) to allow Googlebot.
- Review country/IP blocks: Don’t block Googlebot based on its IP location. Some security services mistakenly include crawler IPs in “high-risk” ranges.
- Check .htaccess or server rules: Rules denying access to directories (like /uploads/ or /pdfs/) may return 403 by default. Update as needed.
- Avoid token-based access on public content: If the page is behind a time-limited token, remove that requirement for crawlers.
Also verify that the 403 isn’t due to user-agent blocking. If Googlebot is disallowed in any part of the stack, the crawl will fail.
After applying fixes, go back to GSC and click “Validate fix” to trigger a new crawl.
If the page is meant to be private (e.g., admin area), then 403 is appropriate — but make sure it’s not linked internally or in your sitemap.
Conclusion
401 and 403 errors are powerful — but misused, they hurt SEO, UX, and API reliability. Use 401 when no authentication is present or valid. Use 403 when a user is authenticated but lacks access.
Monitor, log, and fix these proactively to avoid drops in rankings and user trust.
FAQs
Should I use 401 or 403?
Use 401 for missing/invalid login. Use 403 for denied access despite authentication.Why is 401 unauthorized instead of unauthenticated?
“Unauthorized” historically refers to lack of valid credentials. It’s about authentication.What causes 403 forbidden?
Lack of permissions, server rules, IP blocks, role restrictions.Is 403 forbidden permanent?
It can be. It depends on whether the access policy will ever change.What are the reasons for 401 unauthorized?
No credentials, invalid token, expired session, incomplete login.What is an example of a 403 forbidden?
A logged-in user tries to access a restricted admin area.What are common 403 error scenarios?
Blocked IPs, missing scopes in API tokens, role-based denials.How to get rid of 403 Forbidden?
Adjust access controls, roles, IP filters, and server restrictions.



